
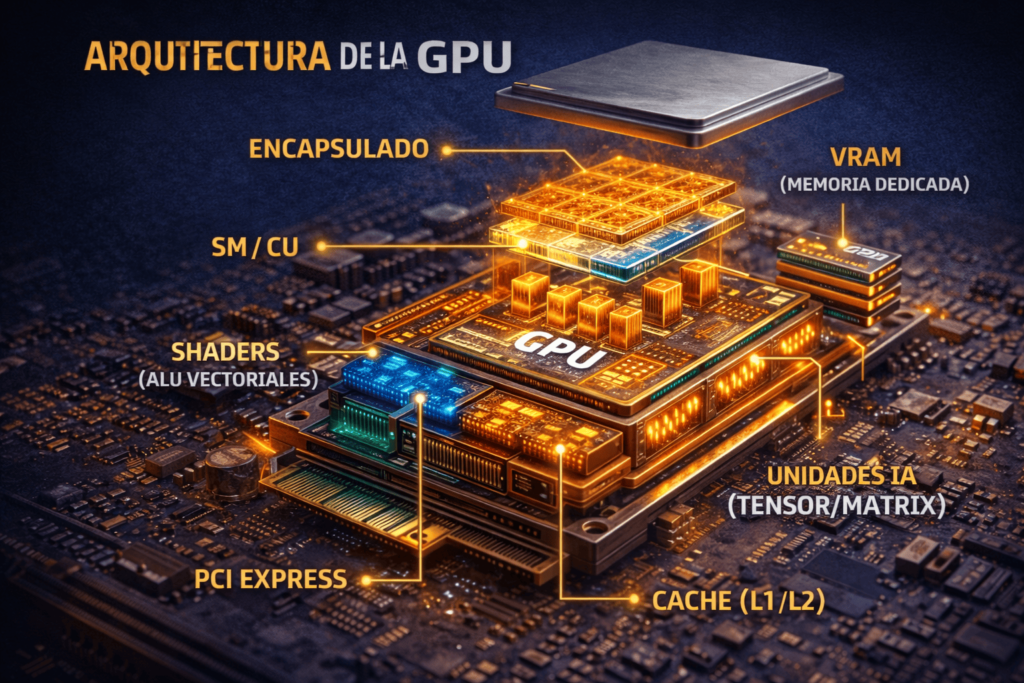
Arquitectura de las GPU modernas: análisis profundo de cada componente interno
Arquitectura de las GPU Modernas: El Corazón del Cómputo Paralelo en 2026
En 2026, la distinción entre una tarjeta gráfica y un acelerador de IA se ha vuelto casi invisible. Ya no compramos simplemente "píxeles por segundo", sino TFLOPS de precisión mixta y capacidad de inferencia neuronal. Esta guía desglosa el silicio desde el transistor hasta el renderizado final.
🧱 1. Encapsulado y Diseño Físico: La Era de los Chiplets
La ley de Moore ha encontrado su límite físico, y la respuesta de la industria ha sido el desagregado del silicio.
Del Monolítico al Diseño Discretizado
- Diseño Monolítico: Tradicionalmente, todas las unidades (Cores, Caché, Controladores) residían en un solo trozo de silicio. Aunque ofrece la menor latencia, es costoso y propenso a defectos.
- Arquitectura de Chiplets (MCM – Multi-Chip Module): Popularizada por AMD y ahora adoptada por Intel y NVIDIA en sectores de alto rendimiento. Se divide la GPU en:
- GCD (Graphics Compute Die): Donde residen los núcleos de cálculo.
- MCD (Memory Cache Die): Donde se ubica la caché L3 y los controladores de memoria.
El Interposer y la Interconexión Óptica
En 2026, las GPUs de gama ultra alta utilizan interconexiones ópticas o puentes de silicio activos para que la comunicación entre chiplets no penalice el rendimiento. Esto permite que una GPU se comporte como un solo procesador lógico, aunque físicamente sean cuatro o más chips trabajando en paralelo.
🧠 2. La Unidad de Cómputo: SM (NVIDIA) vs. CU/WGP (AMD)
Si la GPU es un ejército, el Streaming Multiprocessor (SM) o la Compute Unit (CU) es el batallón fundamental.
Anatomía de un SM de Nueva Generación
Un SM moderno no es solo un grupo de núcleos; es un ecosistema complejo que incluye:
- Registros de gran tamaño: Cruciales para evitar que la GPU tenga que "ir a buscar" datos a la VRAM, lo que causaría latencia.
- L1 Cache / Shared Memory: Un espacio de memoria de bajísima latencia que los hilos usan para comunicarse entre sí.
- Warp Schedulers: Los directores de orquesta que deciden qué instrucción se ejecuta en el siguiente ciclo de reloj.
Dato técnico: En las arquitecturas actuales, el tamaño de la Memoria Compartida ha crecido exponencialmente para satisfacer las demandas de los modelos de lenguaje (LLMs) que corren localmente en la GPU.
🧮 3. Shaders y Unidades de Ejecución: Precisión y Versatilidad
Los "núcleos" ya no son todos iguales. La eficiencia moderna radica en la especialización de la precisión.
Tipos de Unidades de Cálculo
- FP32 (Punto Flotante de 32 bits): El estándar para gráficos de videojuegos.
- FP64 (Doble Precisión): Reservado para simulaciones científicas (dinámica de fluidos, clima).
- INT8 / FP8 / FP4: La clave de la IA. Estas unidades de baja precisión permiten procesar miles de millones de parámetros de redes neuronales con un consumo energético mínimo.
El auge de las Unidades Matriciales
Tanto los Tensor Cores (NVIDIA) como las Matrix Units (AMD/Intel) están diseñados para una sola tarea: multiplicar matrices masivas en un solo ciclo de reloj. Esto es lo que permite que tecnologías como DLSS 4.0 o el escalado por IA generen frames enteros sin que el núcleo gráfico "tradicional" se esfuerce.
🧊 4. Jerarquía de Memoria y el "Muro de la VRAM"
El rendimiento de una GPU en 2026 no lo define cuánto puede procesar, sino qué tan rápido puede mover los datos.
GDDR7 y HBM4: Las nuevas fronteras
| Tecnología | Ancho de Banda Típico | Uso Principal |
| GDDR7 | 1.5 – 2.0 TB/s | Gaming de gama alta y estaciones de trabajo. |
| HBM4 (High Bandwidth Memory) | +4 TB/s | Entrenamiento de IA y Supercomputación. |
La Importancia de la Caché L2/L3 Gigante
Para mitigar el consumo de energía que supone mover datos desde la VRAM, las GPUs modernas (especialmente con la tecnología Infinity Cache de AMD) integran hasta 256MB o 512MB de caché L3. Esto permite que la GPU encuentre los datos necesarios "dentro de casa", aumentando los FPS mínimos y eliminando el stuttering.
🎨 5. El Pipeline Gráfico y el Ray Tracing Asíncrono
El renderizado ha pasado de ser una línea recta a un proceso híbrido y dinámico.
Unidades Especializadas de Ray Tracing (RT Cores)
En 2026, el Ray Tracing ya no es un "extra". Las unidades de intersección de rayos ahora gestionan:
- BVH Traversal (Bounding Volume Hierarchy): El hardware ahora recorre de forma autónoma el árbol de objetos de la escena para ver qué rayo choca con qué objeto, liberando a los Shaders para otras tareas.
- Micro-Mesh Displacement: Permite geometrías infinitamente detalladas sin colapsar la memoria de video.
🔋 6. Gestión de Energía y Telemetría Avanzada
Una GPU moderna realiza miles de ajustes de voltaje y frecuencia por milisegundo.
- Algoritmos de Boost 5.0: La frecuencia ya no es fija. Depende de la temperatura del "Hotspot", el consumo de los VRM (Módulos de Regulación de Voltaje) y la carga de trabajo específica (IA vs Rasterización).
- Degradación y Fiabilidad: Con el paso a procesos de 2nm, la electromigración es una preocupación real. Las GPUs de 2026 incluyen circuitos de monitoreo que ajustan preventivamente las curvas de voltaje para asegurar una vida útil de al menos 10 años.
🧪 7. Diagnóstico basado en Arquitectura para Profesionales
Entender estos componentes permite diagnósticos precisos:
- Si el uso de bus PCIe es alto pero los FPS son bajos: Tienes un cuello de botella de textura o falta de VRAM.
- Si la temperatura del Hotspot supera por 30°C a la Global: El contacto del die con el disipador o el "pump-out" de la pasta térmica es el problema.
- Artefactos en forma de bloques: Generalmente indican fallo en un banco específico de VRAM o en el controlador de memoria, no necesariamente en el núcleo.
La GPU como el nuevo CPU del Sistema
Hemos pasado de una tarjeta que "dibujaba triángulos" a un procesador paralelo que gestiona el lenguaje natural, la física cuántica y los gráficos fotorrealistas simultáneamente. La arquitectura es la que dicta el destino del rendimiento, no los números brutos de la caja.
🔬 SECCIÓN II: Duelo de Titanes en 2026 (Blackwell vs. RDNA 4/5)
Anatomía comparativa de las arquitecturas que dominan el mercado actual.
En 2026, la guerra no es por los MHz, sino por la eficiencia por vatio y la capacidad de cómputo asíncrono.
A. NVIDIA Blackwell / Rubin: El dominio de la Red Neuronal
NVIDIA ha dejado de diseñar GPUs para juegos que hacen IA, para diseñar aceleradores de IA que rinden en juegos.
- Quinto Generador de Tensor Cores: Ahora incluyen soporte nativo para el formato FP4. Esto permite que modelos de lenguaje masivos (LLMs) quepan en la VRAM de una tarjeta de consumo, reduciendo el peso de los pesos de la red neuronal sin pérdida perceptible de precisión.
- Engine de Descompresión NVDEC/NVENC 10.0: Ya no solo codifican video; ahora descomprimen datos de geometría directamente desde el SSD al SM, eliminando por completo al CPU del proceso de carga (Zero CPU Overhead).
B. AMD RDNA 4/5: El triunfo del Chiplet y la Latencia
AMD ha perfeccionado el diseño modular que inició con Ryzen.
- Radiance Display Engine: Soporte total para DisplayPort 2.1 de alto ancho de banda, permitiendo 8K a 165Hz sin compresión.
- Infinity Cache Gen 3: Han implementado una caché L3 "apilada" verticalmente (3D V-Cache en GPU), lo que permite que una tarjeta con bus de 256 bits rinda como una de 512 bits al mantener los datos de las texturas 4K/8K físicamente más cerca de los núcleos de cálculo.
🛠️ SECCIÓN III: Optimización de Software y APIs Modernas (DX12 Ultimate y Vulkan)
Cómo el código "habla" con el silicio para evitar cuellos de botella.
Entender la arquitectura es inútil si el software no sabe pedirle los datos. En 2026, las APIs han evolucionado para ser "conscientes del hardware".
1. Mesh Shaders: El fin del "Culling" tradicional
Antes, el CPU debía decir a la GPU qué objetos no se veían en pantalla para no dibujarlos. Con los Mesh Shaders, la GPU decide por sí misma qué geometría procesar.
- Impacto: Permite escenas con billones de polígonos (microgeometría) con un uso de memoria mínimo.
- Optimización: Los desarrolladores ahora envían "conglomerados" de triángulos, reduciendo las llamadas al sistema (Draw Calls) en un 80%.
2. Sampler Feedback y Variable Rate Shading (VRS)
¿Para qué renderizar al 100% de detalle una zona de la pantalla que está en sombras o desenfocada por el movimiento?
- VRS: Permite que la GPU agrupe píxeles (ej. 2×2 o 4×4) en zonas de bajo detalle, ahorrando hasta un 30% de potencia de cálculo sin que el ojo humano lo note.
- Sampler Feedback: La GPU le dice al motor de juego exactamente qué partes de una textura necesita cargar. Esto evita el stuttering al girar la cámara rápidamente.
🧠 SECCIÓN IV: Anatomía Detallada de la VRAM y Latencia de Inferencia
Por qué 16GB de VRAM en 2026 pueden ser insuficientes o excesivos según su arquitectura.
La VRAM no es un "cubo" donde tiras datos; es una autopista de peaje con carriles limitados.
El subsistema de memoria: GDDR7 al detalle
La llegada de GDDR7 introdujo la modulación PAM3 (Pulse Amplitude Modulation). A diferencia del sistema binario (0 y 1), PAM3 permite tres niveles de señal, lo que dispara el ancho de banda sin aumentar drásticamente el consumo de energía.
Latencia de Acceso vs. Ancho de Banda
- Ancho de Banda (Bandwidth): Cuántos datos pasan por segundo (crítico para texturas 8K).
- Latencia: Cuánto tarda el primer bit en llegar (crítico para la IA y el Ray Tracing).En 2026, el diseño de Memoria Unificada (visto en Apple Silicon y adoptado parcialmente por Intel) está ganando terreno, permitiendo que la GPU y el CPU compartan el mismo pool de memoria de alta velocidad, eliminando el costoso viaje de datos a través del bus PCIe.
El Impacto en la IA Local
Para ejecutar un modelo de IA (como un asistente local), la GPU necesita cargar los "pesos" del modelo en la VRAM.
- Cuello de botella: Si el modelo ocupa 12GB y tu GPU tiene 10GB, el sistema usará la RAM del sistema a través del PCIe, cayendo el rendimiento de 50 tokens/segundo a 2 tokens/segundo. Aquí es donde la arquitectura del bus de memoria define la utilidad real de la GPU.
📈 SECCIÓN V: Guía de Diagnóstico Técnico para Expertos
Cómo identificar qué componente está fallando basándonos en el síntoma.
| Síntoma Gráfico | Componente Probable en Fallo | Razón Técnica |
| Artefactos tipo "Tablero de Ajedrez" | Módulos de VRAM / Controlador | Error de paridad en la escritura de datos de textura. |
| Pantallazo Negro al iniciar carga 3D | VRM / Fases de alimentación | El pico de corriente (Transient Spike) colapsa los reguladores de voltaje. |
| Crasheo con error de Driver (TDR) | Programador de Warps / Shaders | El núcleo intentó una instrucción ilegal o entró en un bucle infinito (Divergencia). |
| Baja de FPS súbita tras 15 min | Thermal Throttling (Hotspot) | El sensor de temperatura interno ordena bajar el voltaje para proteger el silicio. |
🔦 SECCIÓN VI: El Pipeline de Ray Tracing y la Aceleración por Hardware
De la ecuación de renderizado al silicio: Cómo la GPU "entiende" la luz.
El trazado de rayos simula el comportamiento físico de los fotones, pero a la inversa (desde la cámara hacia la fuente de luz). Este proceso es computacionalmente prohibitivo para los núcleos tradicionales (Shaders), lo que dio origen a los RT Cores.
1. El Algoritmo BVH (Bounding Volume Hierarchy)
El mayor desafío del Ray Tracing no es el rayo en sí, sino saber con qué choca. En una escena con 100 millones de polígonos, sería imposible calcular cada intersección.
- La Estructura de Árbol: La GPU organiza la escena en cajas dentro de cajas (volúmenes envolventes).
- BVH Traversal: El RT Core recorre este árbol. Si un rayo no toca la "caja grande", descarta instantáneamente todos los objetos dentro de ella.
- Innovación en 2026: Las GPUs modernas ahora realizan el recorrido del árbol (Traversal) de forma totalmente asíncrona. Mientras los núcleos CUDA/Stream Processors calculan el color de un píxel, el RT Core ya está buscando el siguiente choque de luz en segundo plano.
2. Anatomía de la Intersección: El RT Core al detalle
Dentro de un SM (NVIDIA) o una CU (AMD), el RT Core tiene dos funciones críticas:
- Box Test Unit: Determina si el rayo entra en una caja del BVH.
- Triangle Test Unit: Una vez que el rayo está cerca del objeto, calcula la intersección matemática exacta con el triángulo de la malla.
Ecuación de Intersección (Simplificada):
Para que la GPU determine el punto de choque $P$ de un rayo con origen $O$ y dirección $D$, utiliza la ecuación:
$$P(t) = O + tD$$
Donde $t$ es la distancia. El hardware debe resolver esta ecuación para miles de millones de rayos por segundo, buscando el valor de $t$ más pequeño (el objeto más cercano).
3. Ray Reordering: La clave de la eficiencia en 2026
Uno de los problemas históricos del RT era la divergencia. Los rayos rebotan en todas direcciones, lo que causaba que la caché de la GPU se vaciara constantemente (cache misses).
- SER (Shader Execution Reordering): Introducido por NVIDIA y perfeccionado en 2026. La GPU analiza miles de rayos desordenados, los agrupa por dirección o material similar, y los envía a los shaders en bloques coherentes.
- Resultado: Un incremento de hasta el 300% en el rendimiento de Path Tracing (trazado de caminos completo) en comparación con arquitecturas que no reordenan hilos.
🌌 4. Path Tracing vs. Ray Tracing Híbrido
En 2026, hemos superado el "Ray Tracing de efectos" (solo reflejos o sombras).
- Ray Tracing Híbrido: Usa rasterización para la geometría visible y rayos solo para sombras y reflejos específicos.
- Full Path Tracing (Realtimes): Cada píxel es el resultado de múltiples rebotes de luz, incluyendo iluminación global indirecta, dispersión subsuperficial (en la piel) y cáusticas (luz a través de cristal/agua).
- El papel de la IA: Dado que el Path Tracing genera una imagen con "ruido" (puntos negros), los Tensor Cores entran en acción con algoritmos de Denoising Espacial-Temporal, reconstruyendo la imagen final a partir de apenas un 10% de los rayos necesarios.
⚡ SECCIÓN VII: Micro-Mesh y Desplazamiento por Hardware
Para evitar que el Ray Tracing consuma toda la VRAM, las GPUs de 2026 utilizan Micro-Mesh Displacement.
Tradicionalmente, para un suelo de piedra detallado, necesitabas millones de triángulos reales. Ahora:
- Se envía una malla base simple (pocos triángulos).
- El RT Core aplica un mapa de desplazamiento en tiempo real durante el trazado del rayo.
- Ventaja: Ahorro masivo de memoria VRAM (hasta 10 veces menos espacio) y carga de datos casi instantánea desde el SSD.
🌡️ SECCIÓN VIII: Gestión Térmica y el "Power Wall" de los 600W
No podemos hablar de arquitectura sin hablar de calor. En 2026, el diseño físico de las GPUs ha cambiado para sobrevivir a densidades de transistores extremas.
- Vapor Chambers de Fase Dual: El líquido refrigerante dentro de la cámara de vapor ahora tiene micro-canales optimizados por IA para dirigir el calor lejos del "Hotspot" del silicio.
- Transient Spikes (Picos Transitorios): Las GPUs modernas pueden pedir picos de energía de más de 1,000W durante microsegundos. La arquitectura incluye ahora condensadores de alta densidad en el propio encapsulado (on-package) para filtrar estos picos sin apagar la fuente de poder (PSU).
⚡ SECCIÓN IX: GPGPU (General Purpose GPU) – La Era de la Computación Paralela
En 2026, una GPU ya no "dibuja". La GPU procesa datos. La rasterización es solo una tarea secundaria dentro de un ecosistema mucho más amplio.
1. El Concepto de "Kernel" y Latencia
Un Kernel es una función pequeña que se ejecuta miles de veces en paralelo. La arquitectura de la GPU está diseñada para minimizar el Kernel Launch Latency.
- Memory Coalescing (El Santo Grial): El cuello de botella no suele ser la velocidad del núcleo, sino cómo se accede a la VRAM. Si 32 hilos (un Warp) intentan acceder a direcciones de memoria contiguas, el controlador de memoria puede leer todo en una sola operación (coalesced access). Si acceden a direcciones dispersas (uncoalesced), el rendimiento cae hasta un 90%.
- Gestión de Registros: Los kernels complejos usan muchos registros. Si el kernel ocupa demasiados registros, el SM no puede ejecutar suficientes Warps al mismo tiempo para ocultar la latencia de memoria, lo que resulta en un SM "ocioso".
2. Jerarquía de Precisión: El nuevo paradigma
Para 2026, la eficiencia se mide en TFLOPS por vatio y la precisión es flexible. El diseño de los núcleos ahora prioriza la "precisión mixta":
| Tipo de Precisión | Aplicación | Eficiencia |
| FP64 | HPC, Simulaciones Científicas | Muy baja |
| FP32 | Gráficos estándar, Renderizado 3D | Media |
| FP16 / BF16 | Inferencia de IA (estándar) | Alta |
| FP8 / FP4 | Entrenamiento de LLMs y visión por computador | Extrema |
La arquitectura moderna tiene unidades de ejecución que pueden dividir un núcleo FP32 en dos núcleos FP16, duplicando el rendimiento para tareas de IA sin aumentar el tamaño físico del chip.
🎞️ SECCIÓN X: El Motor de Multimedia (Fixed-Function Hardware)
Mucha gente cree que los "Shaders" hacen todo. Falso. Una parte significativa del die de la GPU está dedicada a Fixed-Function Hardware, bloques de silicio que solo saben hacer una cosa y la hacen extremadamente bien.
1. NVENC/NVDEC y VCN (Video Coding Engine)
Estos bloques no usan núcleos CUDA ni Stream Processors. Son circuitos lógicos dedicados.
- ¿Por qué dedicados? Porque procesar video con shaders sería un suicidio energético. Un encoder fijo consume una fracción de la potencia de una GPU, permitiendo grabar en 4K mientras juegas sin afectar los FPS.
2. AV1 y H.266 (VVC – Versatile Video Coding)
En 2026, el soporte de hardware para VVC es la norma.
- AV1: Es el estándar de oro para el streaming debido a su alta eficiencia de compresión sin regalías.
- H.266: Supera a HEVC (H.265) en un 50% de eficiencia.
- Data Flow: El flujo de datos es:
SSD -> Bus PCIe -> Decoder (Fixed-Function) -> VRAM -> Display Engine.- Nota importante: El CPU apenas toca los datos. Si ves que tu CPU sube al 100% al reproducir video, tu GPU no está utilizando su motor multimedia dedicado o el driver no está configurado correctamente.
🔍 SECCIÓN XI: Anatomía del Bus PCIe y el "Lado Oscuro" de la Interconectividad
Para entender la arquitectura, debemos mirar qué pasa fuera del chip. El bus PCIe es la "tubería" que conecta la GPU con el mundo.
El problema de la transferencia
La GPU es asombrosamente rápida, pero el bus PCIe es una "paja" comparado con la velocidad interna de la memoria (HBM3/GDDR7).
- PCIe 5.0 x16: Ofrece ~64 GB/s. Parece mucho, pero una GPU moderna mueve terabytes por segundo internamente.
- DirectStorage: Esta tecnología (adoptada de las consolas) permite que la GPU descomprima los datos directamente desde el almacenamiento.
- Arquitectura:
SSD (NVMe) -> DMA (Direct Memory Access) -> GPU VRAM. - Esto elimina el cuello de botella de la CPU, permitiendo que el hardware maneje el flujo de datos sin latencia de interrupción.
- Arquitectura:
📈 Resumen Técnico: El estado del arte en 2026
Para cerrar esta expansión:
- Cómputo: Dominado por arquitecturas altamente especializadas en Mixed Precision (FP8/FP4).
- Multimedia: Desplazado totalmente hacia bloques Fixed-Function para maximizar la eficiencia.
- Memoria: El bus de datos externo (PCIe) es el mayor cuello de botella; la tendencia es la Memoria Unificada y la transferencia directa (DirectStorage) para evitar al CPU.